


An Introduction to Genomic Sequencing
Estimated Reading Time: 5 minutes

TL;DR
Genomic sequencing has rapidly advanced the human ability to quantitatively investigate biological systems. Sequencers have grown capable of reading ever larger strands of DNA for ever lower costs. The growing accessibility of sequencing technology has enabled a host of applications in basic biology, therapeutics design, diagnostics, and more. In today’s issue, we survey the landscape of sequencing and comment about some of the frontiers on the horizon.
A Quick Logistical Note
We’re excited to welcome our readers back to a new series on technologies used in modern biotech! We’ve got a lot of exciting new initiatives underway at Deep Forest Sciences, so this new sequence will follow a more irregular publication schedule, with issues roughly targeted for every other week covering a range of topics in biotech. Follow us on Twitter at @deepforestsci to stay abreast of our releases.
DNA Basics

{kind=link}
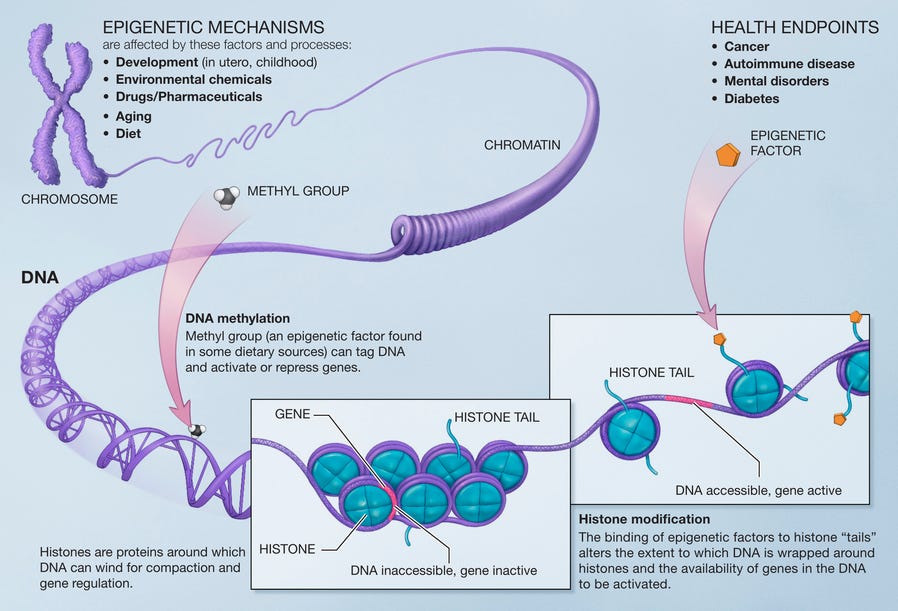
DNA, deoxyribonucleic acid, is the fundamental information coding molecule for biological systems. Genetic information is encoded as sequences of base pairs A/T/C/G (see image above). DNA is used to generate RNA (in a process called transcription), and the RNA is used to construct proteins (in a process called translation). In theory, knowing the genome, that is the full sequence of genetic information, should provide a blueprint that enables understanding nearly everything about the organism. In practice of course, the situation is much more complex. The “program” that DNA encodes is extraordinarily complicated, and modern science has only started to understand how gene expression works in practice. As the figure below shows, the field of epigenetics has revealed that there are a number of heritable modifications to genomes that aren’t represented in the base pair sequence. Nonetheless, access to the full genome provides a powerful starting point for subsequent biological study.
The experimental process used to determine the sequence of base pairs of a genome is called sequencing. There have been hosts of different DNA sequencing technologies developed over the last few decades as the figure below shows. Sanger sequencing was widely used for decades but has recently started to be displaced by more modern methods such as nanopore sequencing.

{kind=link}
The technologies used for sequencing large strands of DNA vary, but in general follow a series of steps roughly like those in the figure below. A long DNA sequence is fragmented, cloned into viral vectors, and grown in bacteria. The fragments are then sequenced and computationally re-assembled. It’s important to note that modern approaches like nanopore sequencing can bypass the need for DNA fragmentation (we will have more to say in a future issue).

{kind=link}
DNA Sequencing’s Rapid Drop in Price
The cost of sequencing has dropped dramatically over the last few decades from about $100 million at the start of the millennium to a little over a thousand dollars per genome today. A series of technological breakthroughs powered this precipitous drop in cost.

{kind=link}
Price drops have stagnated over the last few years, but recently the PRC’s Beijing Genomics Institute (BGI) has claimed to achieve a $100 genome. BGI cooperates closely with the PRC government and has been tied to the ongoing atrocities in Xinjiang. Working with PRC companies is risky at best (BGI has been implicated in patent infringement for example (source)) and unethical or illegal at worst (due to ties to Xinjiang), so companies choosing to partner with BGI are taking on considerable risk. A number of American and other firms including Illumina are now racing to offer competing $100 genomic sequencing products (source).
Downstream Use Cases of Sequencing
Rapidly dropping costs for sequencing have enabled a broad range of applications. Sequencing is used to power liquid biopsies for early cancer diagnosis, characterize human microbiomes and rare diseases,, and discover new drugs for specific targets. We’ll have more to say on these applications in future issues!
Weekly News Roundup
https://forum.deepchem.io/t/deepchem-model-wishlist-internships/569: The DeepChem project is partnering with Deep Forest Sciences, CMU and ARPA-E to sponsor internships to implement scientific machine learning models in the DeepChem open source library.
https://www.wsj.com/articles/ford-and-gm-scale-back-production-amid-chip-shortage-11630605601: Chip shortage issues continue to cause serious slowdowns in manufacturing.
Feedback and Comments
Please feel free to email me directly (bharath@deepforestsci.com) with your feedback and comments!
About
Deep Into the Forest is a newsletter by Deep Forest Sciences, Inc. We’re a deep tech R&D company specializing in the use of AI for deep tech development. We do joint development partnerships with deep tech firms. Get in touch with us at partnerships@deepforestsci.com! We’re always welcome to new ideas!
Credits
Author: Bharath Ramsundar, Ph.D.
Editor: Sandya Subramanian, Ph.D.