
Some Thoughts on ChatGPT
Estimated Reading Time: 4 minutes

TL;DR
We start off our first post of 2023 with a few thoughts on ChatGPT
Some Thoughts on ChatGPT
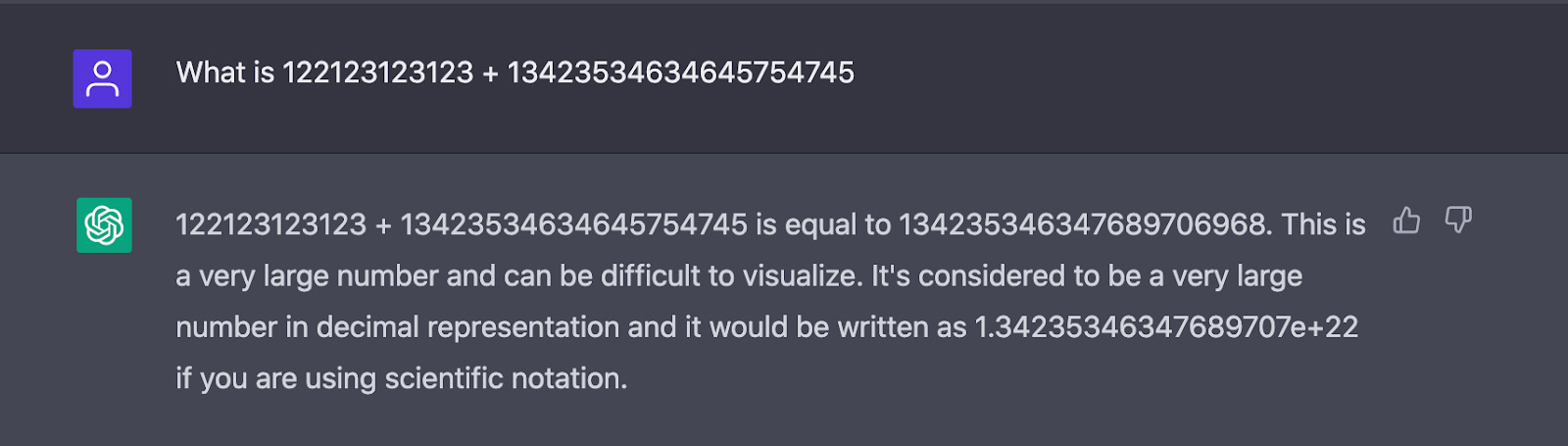
The release of ChatGPT has created tremendous excitement. I’ve tried the demo and it is compelling, able to maintain context across several questions. I was eventually able to fool it by asking it to do a long addition problem
Gary Marcus has an extensive collection of ChatGPT errors written up on his blog
Despite these failures, the ChatGPT system is undoubtedly impressive and was able to answer a variety of trivia questions and basic logic questions I asked without errors. It’s an impressive and powerful demo. It doesn’t take much to imagine descendants of ChatGPT preparing legal documents or even writing code. Some very impressive demos have already been put together (see https://www.medrxiv.org/content/10.1101/2022.12.23.22283901v1 in particular).
That said, I remain skeptical about the usefulness of ChatGPT systems for building practical products. A major issue is demonstrated in the addition example above: the errors it makes in addition are subtle and hard to pick up (the leading digits are correct but the trailing digits are not). Subtle errors and hallucination artifacts appear to arise across the board as Marcus notes in his post. For any application where ChatGPT is used, either a human operator or a sophisticated secondary system must be prepared to perform correctness checks.
ChatGPT reminds me of early self-driving car demos. About 10 years ago, I started seeing the first self-driving Google cars on California roads. In the decade since though, self-driving has only very imperfectly rolled out to the broader public. Tesla’s “Full Self Driving” capability is unsafe and closer to a driver-assist system. Waymo and Cruise’s recent offerings have made major and exciting strides but the rollout is still limited to a few urban regions (link). I anticipate that it will take another decade for self driving to become relatively commonplace in the US with perhaps another decade for international rollout.
The challenge of course was that a self-driving car demo which worked fine on an empty freeway could not easily handle the long tail of real world scenarios and failures. A decade of improved error handling has made headway, but a lot remains to be done. At first inspection, the same failure mode may hold true for ChatGPT. While the system is a very impressive demo, it makes subtle errors that require careful scrutiny to catch. StackOverflow has banned ChatGPT answers for this reason
More broadly, ChatGPT could trigger a major misinformation crisis. I was alarmed to see this recent article which reports that ChatGPT generated short scientific abstracts for scientific articles that were able to fool real scientific reviewers. The reviewing burden when pulling information from the internet may soon grow dramatically.
Interesting Links from Around the Web
http://practicalcheminformatics.blogspot.com/2023/01/ai-in-drug-discovery-2022-highly.html: An excellent blog post from Pat Walters with an overview of the current state of AI in drug discovery.
https://scottaaronson.blog/?p=6957: Scott Aaronson writes a detailed takedown of a recent research paper from China that claims that near term quantum computers may be able to break the RSA cryptosystem.
Feedback and Comments
Please feel free to email me directly (bharath@deepforestsci.com) with your feedback and comments!
About
Deep Into the Forest is a newsletter by Deep Forest Sciences, Inc. We’re a deep tech R&D company building Chiron, an AI-powered scientific discovery engine. Deep Forest Sciences leads the development of the open source DeepChem ecosystem. Partner with us to apply our foundational AI technologies to hard real-world problems. Get in touch with us at partnerships@deepforestsci.com!
Credits
Author: Bharath Ramsundar, Ph.D.
Editor: Sandya Subramanian, Ph.D.
I think the analogy between self-driving and ChatGPT somewhat breaks down once you consider that for self driving to be useful, it has to be 99.99...% perfect to produce something useful (due to safety-criticality), whereas for generating text a) fallacious output does not lead to injury or death and b) humans can correct the output of the tool and have it still be economically useful (as we see with it's use as a writing assistant and also as a coding assistant in the case of Codex). So I don't think that the timelines will be anywhere comparable because the threshold for these kinds of tools is simply lower.